How to Get AI Help with Coding Locally
Local coding agents are great. Instead of relying on cloud-based services, you can now run powerful AI coding assistants entirely on your own hardware. In this guide, we’ll walk through setting up LM Studio with Qwen Code, giving you a local coding CLI agent you can use anywhere.
What you’ll need
- LM Studio → to run large language models locally and expose them via an API
- Qwen Coder models → in particular
qwen/qwen3-coder-30b. You’ll find these in LM Studio. - Node.js + npm → required to install Qwen Code. Check out NVM on windows.
- Qwen Code CLI → coding agent you’ll use from the terminal
Step 1: Install LM Studio
LM Studio is a desktop application that lets you run large language models locally, complete with a simple chat interface and a developer-friendly API server.
Download and install LM Studio for your operating system. Once installed, you’ll have a clean interface for loading and running models.
Step 2: Select the model
For this example, we’ll use:
qwen/qwen3-coder-30bWhen you select a model, LM Studio will show the estimated VRAM and RAM requirements. Before going further, it’s a good idea to test the model in the LM Studio chat tab. See how it performs in practice.
Step 3: Tweak the settings
LM Studio allows per-model settings. Open the model folder, click the settings icon, and review the available options. Key things to consider:
- Force expert weights onto CPU → lets you offload the MoE (Mixture of Experts) layer to the CPU, which often speeds things up significantly.
- Flash Attention → can improve performance.
- Context length → the longer, the better (but higher VRAM usage). I’m using
50kmyself.
After adjusting, load the model once in the chat tab. Keep Task Manager (or your system monitor) open to watch VRAM and RAM.
While you’re chatting, hover the small stopwatch icon in the message header to see tokens per second — aim for ~20 tok/s or better. Faster is, of course, better.
Step 4: Start the LM Studio server
To connect external tools to LM Studio, you’ll need to start its API server. The documentation shows the details, but the basic command looks like this:
lms server start --port 1234This will spin up a local server on port 1234, which other tools can connect to.
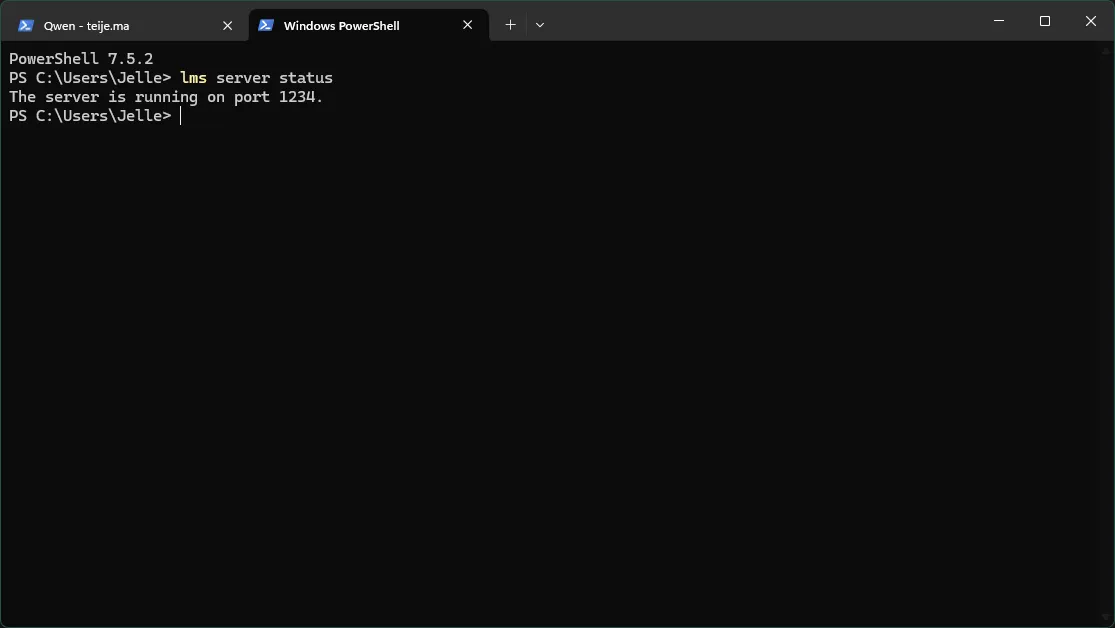
To confirm it’s running, you can use:
lms server statusThat gives you a quick overview of the server state.
Step 5: Install and configure Qwen Code
Qwen Code is a command-line AI workflow tool optimized for Qwen-Coder models. It lets you query, refactor, and generate code directly from your terminal. To install it, you’ll need Node.js 20 or higher and npm available on your system.
Install globally with npm:
npm install -g @qwen-code/qwen-code@latestCheck the installation:
qwen --versionIf the version number prints, you’re good to go.
Connecting Qwen Code with LM Studio
By default, Qwen Code wants to connect to Qwen’s own APIs. To use your local LM Studio server instead, you’ll need to create a .env file in the project folder where you want to work:
OPENAI_API_KEY=123
OPENAI_BASE_URL=http://localhost:[your-port]/v1
OPENAI_MODEL=qwen/qwen3-coder-30bOPENAI_API_KEYcan be any placeholder value (LM Studio doesn’t check it).OPENAI_BASE_URLmust match the port you set when starting the LM Studio server (for examplehttp://localhost:1234/v1).OPENAI_MODELshould be the model you loaded into LM Studio.
Once the .env file is in place, you can start Qwen Code by simply typing:
qwenMake sure you run this command inside the folder with your .env file. Qwen Code will automatically pick it up and route requests through your local LM Studio server.
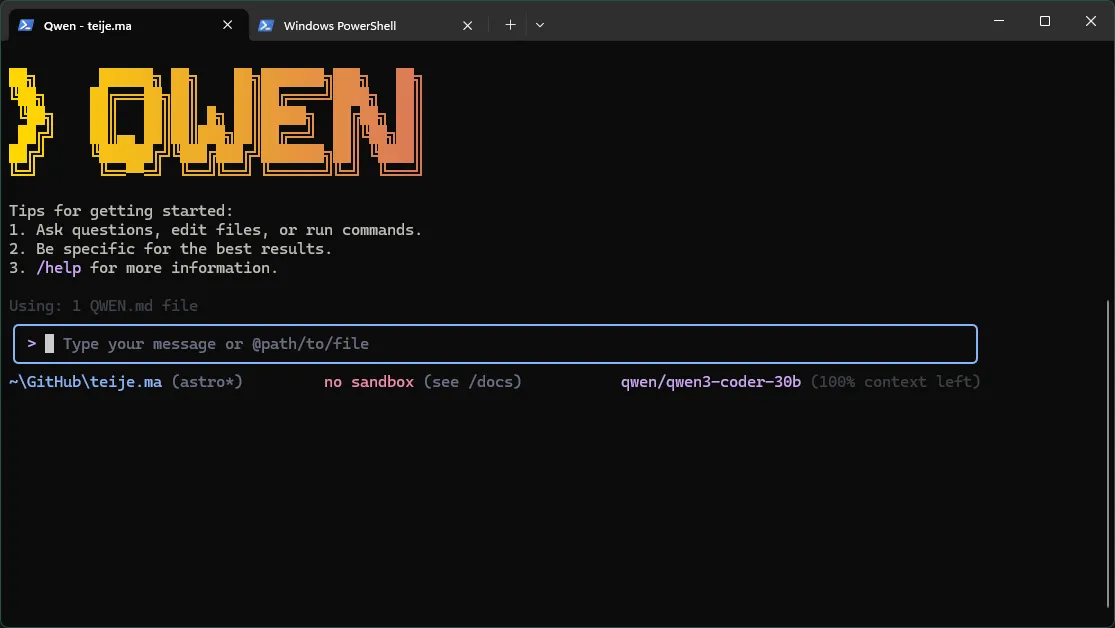
From there, you can begin chatting with the coding agent. For example:
Help me refactor this function
Generate unit tests for this moduleQwen Code will use your local model for all requests — no cloud involved.
Step 6: Project-Specific Memory & Configuration for Qwen Code
Qwen Code supports project-specific memory and configuration, allowing you to tailor the agent to each project and re-use that context across sessions. The official documentation is a great starting point: see Qwen Code docs index.
For details on CLI configuration options and settings, check out the Configuration guide.
Why Use a .qwen Folder?
It’s helpful for keeping your project-specific context and preferences in sync. Here’s how you can set it up:
- In your project directory, create a
.qwenfolder. - Inside it, add:
-
QWEN.md— a README-style file describing your project, its purpose, key modules, or any context the LLM should “remember.” -
settings.json— for CLI settings such as session token limits, e.g.:{ "sessionTokenLimit": 32000 }This helps control how long your LLM session can grow before being compressed or cleared. Set it to the context limit you picked in
lm studio
-
When you start qwen in this folder, those files will help the CLI pick up the right context and tools automatically—no more re-explaining your project every session.
Refreshing Memory On-The-Fly
Already running Qwen Code? Just run:
/memory refreshThis command reloads your QWEN.md into the current session, so any updates you made will be applied immediately.
Quality of Life & Workflow Tips
Once you have Qwen Code running against LM Studio, there are a few tricks to make your life easier.
Useful Commands
/help→ list available commands/clear→ reset the current conversation/stats→ check your current token usage and session details/compress→ shrink history to fit within your session token limit/memory refresh→ reload the contents of yourQWEN.mdfile on the fly
These are worth memorizing — they keep your session fast and manageable.
Example Workflows
A few ways you might use Qwen Code day-to-day:
# Explore a new repo
cd my-project
qwen
> Summarize the key modules in this repo
> Describe how data flows between backend and frontend
# Improve code quality
> Suggest error handling improvements for src/api.js
> Generate unit tests for src/utils/formatDate.ts
# Automate repetitive tasks
> Find all TODO comments and make a changelog
> Refactor this large class into smaller modulesThe agent shines when you let it “hold the map” of your project, so you can focus on higher-level coding decisions.
Closing Note
With LM Studio and Qwen Code, you’ve now got a self-contained AI coding assistant running entirely on your own hardware. No API bills, no external dependencies — just you, your machine, and the model of your choice.